
Solana has long stood at the frontier of blockchain innovation, but its latest initiative - the Solana LLM benchmark - signals a new era in AI and decentralized finance. With the recent launch of Solana Bench, developers and researchers finally have a reproducible, open-source framework for evaluating how effectively large language models (LLMs) can generate and execute on-chain transactions using Solana’s robust SDKs and DeFi protocols. This is more than just a technical milestone; it’s a leap forward in making AI an operational partner within the Solana ecosystem.

Why Benchmarking AI on Solana Matters in 2025
The convergence of blockchain and AI is one of 2025’s defining tech trends. As Solana’s price sits at $211.50, up and 0.0458% in the past 24 hours (source), attention isn’t just on price action but on how smart these networks can become. The challenge: until now, there was no objective way to measure if LLMs could actually build, sign, and submit transactions on-chain without human oversight. As Noah Gundotra from Solana put it, “How well can LLMs actually build transactions on Solana? Until now, there wasn’t a simple, reproducible way to measure. ”
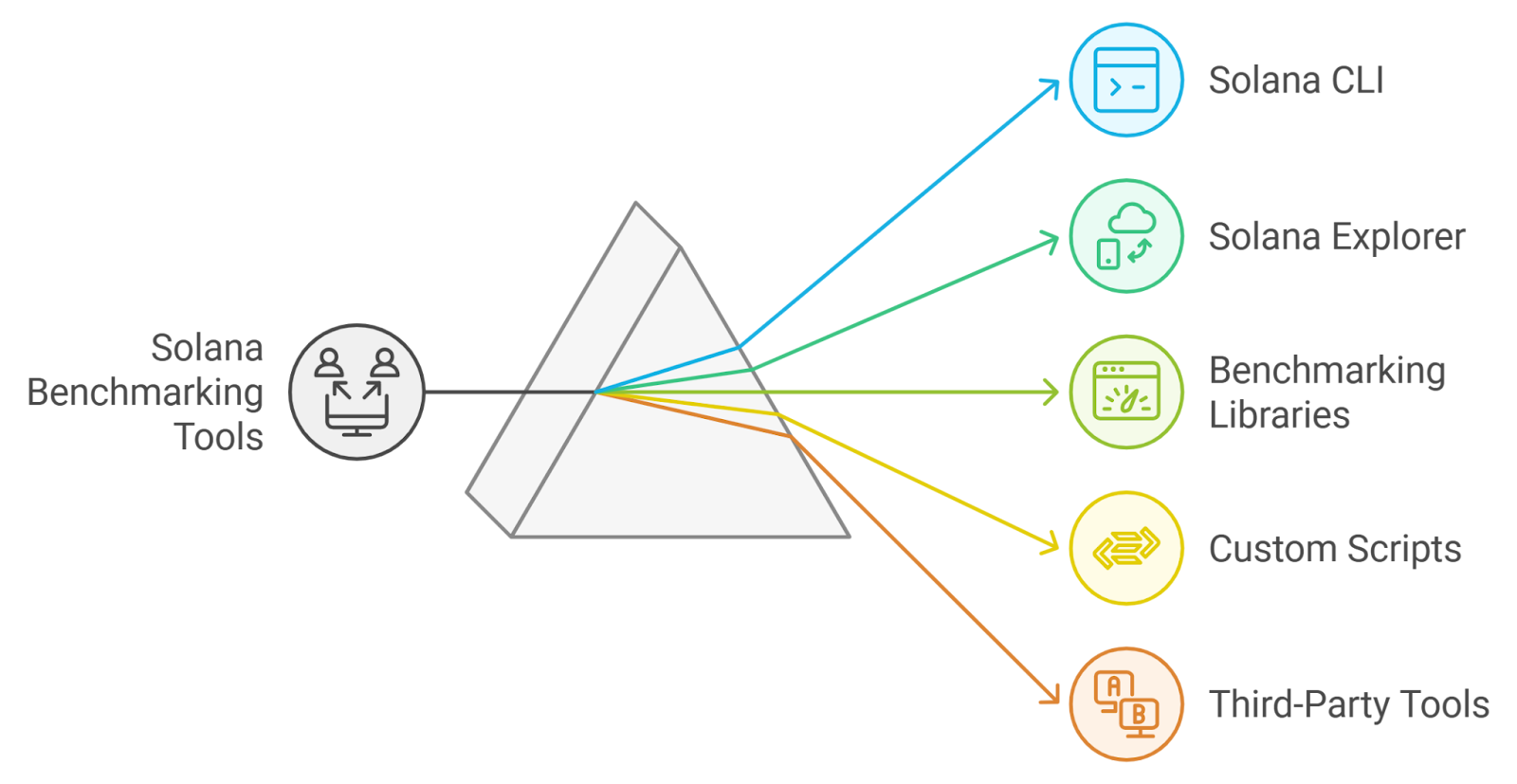
Solana Bench fills this gap by providing standardized tasks that mimic real-world developer operations: wallet creation, token swaps, NFT minting, DeFi interaction, and more. Each task is scored for correctness and efficiency, creating a transparent leaderboard for AI agents working with blockchain data.
The Mechanics Behind Solana Bench: What Gets Tested?
The core innovation with Solana Bench lies in its task-driven evaluation suite. Here’s what makes it unique:
- Operational Competence: Can an LLM write code that compiles against real Solana SDKs?
- Error Handling: Does the model gracefully recover from common transaction failures?
- Ecosystem Breadth: Are DeFi protocols like Raydium or NFT standards like Metaplex supported out-of-the-box?
- User Experience: How well does the agent explain its process or suggest next steps to non-technical users?
This approach moves beyond simple Q and A or code completion benchmarks. It tests whether an AI agent can operate as a self-sufficient blockchain developer - an essential step if we want autonomous agents managing wallets or executing trades safely.
The Visual Layer: Insights That Drive Adoption
A key feature of modern benchmarking tools is their visual insights dashboards. MathVista, for example, has popularized visual reasoning benchmarks where models must interpret graphs or charts before answering questions - crucial for DeFi analytics bots or trading agents.
Solana Bench visual dashboards take this further by letting users drill down into each test case: see where models fail (like missing nonce errors), compare performance across different LLMs (think GPT-5 vs Claude 4), and even visualize transaction flows step-by-step. This transparency is vital for both developers seeking to improve their models and enterprises evaluating which AI agents to trust with real assets.
Top 5 Use Cases Enabled by LLM Benchmarking on Solana
- 1. Automated Onchain Transaction GenerationSolana Bench allows LLMs to be rigorously tested on their ability to generate and execute real Solana transactions using the Solana SDK, paving the way for AI-powered DeFi automation and smart contract interactions.
- 2. Enhanced Security for AI AgentsBy benchmarking LLMs' operational competence, platforms like Arc can ensure that autonomous AI agents interacting with Solana maintain high standards of security and reliability, reducing risks in onchain operations.

- 3. Decentralized AI Task CoordinationWith frameworks like Sollong leveraging Solana Bench, users can submit AI tasks via mobile apps, which are then securely coordinated and verified on Solana’s blockchain—enabling trustless, decentralized AI services.

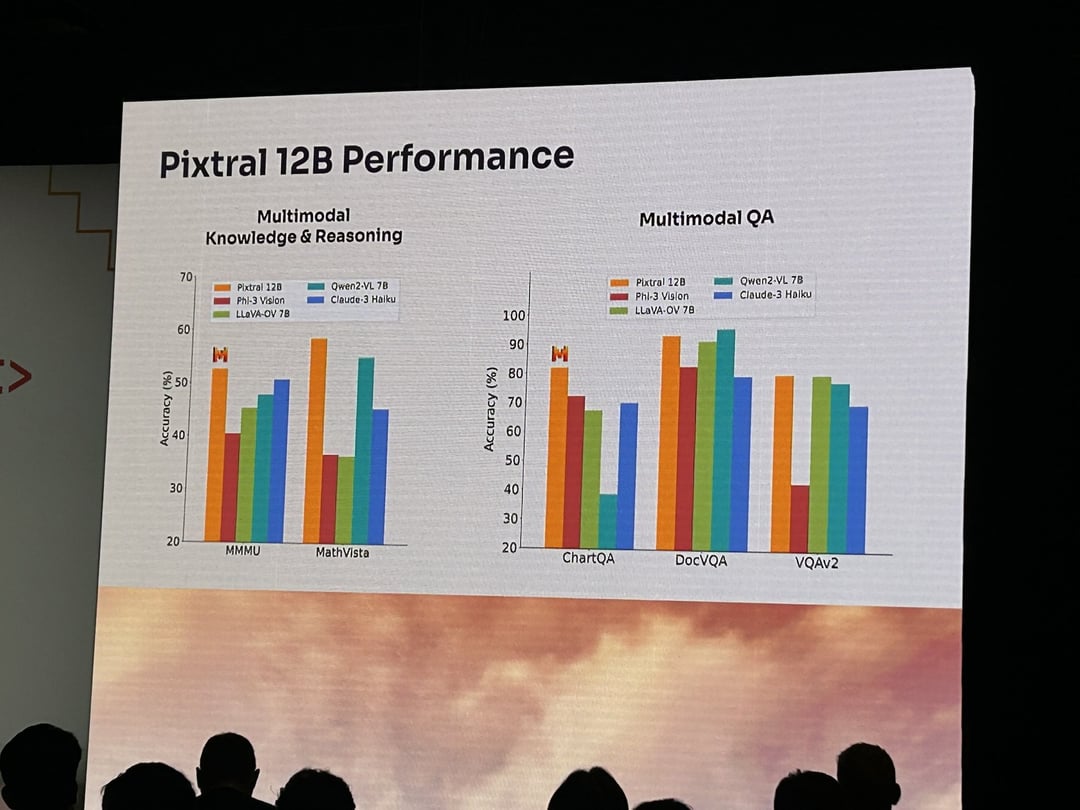
- 4. Improved Visual Reasoning for Blockchain AnalyticsBenchmarks such as MathVista and ChartQA are now being used alongside Solana Bench to assess LLMs' ability to interpret onchain data visually, supporting advanced analytics and data-driven decision making in the Solana ecosystem.
- 5. Transparent Evaluation and Model SelectionTools like LLM Comparator and LLMMaps enable developers to compare LLMs’ performance on Solana-specific tasks, ensuring transparent, data-driven selection of the best models for blockchain applications.

This visual-first approach not only supports technical debugging but also builds trust among non-developers who want to understand how their assets are managed by autonomous agents.
As the Solana ecosystem matures in 2025, these advances in benchmarking are more than just a developer convenience, they are foundational for scaling trustless finance. With Solana Bench, the community can now objectively compare how different large language models perform on practical blockchain tasks, from basic wallet management to orchestrating complex DeFi strategies. This is particularly crucial as more on-chain AI agents emerge, capable of integrating market data, social signals, and even regulatory reasoning into their operational logic.
Projects like Sollong and Arc are already leveraging these benchmarks to push the boundaries of what’s possible in decentralized AI coordination. Sollong enables users to submit AI tasks via mobile apps, while Arc provides secure sandboxes for autonomous agents interacting with live blockchain data. The result? A new breed of applications where LLMs not only interpret information but also act, executing swaps, managing portfolios, or even arbitraging across protocols, all natively on Solana.
Comparing LLMs: Visual Leaderboards and Transparent Metrics
The rise of tools like LLM Comparator and LLMMaps underscores a broader shift toward transparent model assessment. These platforms let users run side-by-side evaluations and visualize granular performance metrics across coding, reasoning, and knowledge domains. For Solana developers, this means faster iteration cycles, the ability to pinpoint exactly where a model’s logic fails (for example, mishandling token decimals or missing required signatures) and fix it before deploying on mainnet.
Visual dashboards also foster community-driven improvement: open leaderboards encourage healthy competition among model providers while providing real-world feedback loops that drive rapid progress. As LLMs climb the ranks in operational competence, especially with the latest generation like GPT-5, these benchmarks will shape which agents become trusted fixtures in DeFi infrastructure.
Why This Matters for Investors and Builders Alike
The implications stretch far beyond technical circles. For investors watching Solana hold strong at $211.50, these innovations signal a maturing ecosystem where automation is not just possible but measurable and improvable. Autonomous trading bots, NFT marketplaces run by AI agents, or even compliance-checking smart contracts all depend on reliable benchmarking to ensure safety and efficiency.
This is why standardized frameworks like Solana Bench aren’t just for coders, they’re essential infrastructure for anyone who wants to see blockchain AI move from hype to utility. By making performance transparent and reproducible, they lower the barrier for new projects to build with confidence, and for enterprises to allocate capital into truly intelligent DeFi products.
Top 5 LLMs Leading Solana Bench in 2025
- GPT-5 by OpenAI: Renowned for its advanced reasoning, coding, and transaction-building skills, GPT-5 consistently tops Solana Bench leaderboards for operational competence, particularly in DeFi protocol integration and smart contract execution.

- Claude 3 Opus by Anthropic: Claude 3 Opus excels in secure transaction generation and onchain reasoning, making it a favorite for Solana-based AI agents and blockchain automation tasks.
- Gemini 2 Ultra by Google DeepMind: With robust multimodal capabilities, Gemini 2 Ultra demonstrates strong performance in both code generation and visual reasoning benchmarks, including MathVista and ChartQA, on the Solana Bench.

- Llama 3-70B by Meta AI: Llama 3-70B is celebrated for its open-source flexibility and competitive results in transaction simulation and execution on Solana, appealing to developers seeking transparency and customization.

- Mixtral 8x22B by Mistral AI: The Mixtral 8x22B model stands out for its efficiency and reliability in handling complex Solana SDK operations, earning high marks for both speed and accuracy on operational leaderboards.

Looking Ahead: The Roadmap for Blockchain-AI Integration
With visual insights now at the core of benchmarking tools, and open protocols like Solana leading the charge, expect rapid acceleration in both model quality and application diversity over the next year. As benchmarks evolve to include multimodal reasoning (text plus charts or code), legal compliance checks, and even adversarial testing scenarios, we’ll see smarter agents that can safely handle increasing responsibility within DeFi ecosystems.
The bottom line? The launch of Solana Bench is more than a technical milestone, it’s a statement about where Web3 intelligence is headed: transparent, accountable, and deeply integrated with real-world financial operations. For builders and investors alike, this marks an inflection point worth watching closely as Solana continues its push toward mainstream adoption, at $211.50, its value reflects not only market optimism but growing confidence in its technological leadership.




No comments yet. Be the first to share your thoughts!